
- Evangelische Hochschule Nürnberg
- Hochschule Ansbach
- Hochschule Augsburg
- Hochschule Hof
- Hochschule Neu-Ulm
- Technische Hochschule Ostwestfalen-Lippe
- Hochschule Weihenstephan-Triesdorf
- Open Resources Campus NRW (ORCA.nrw)
- Virtuelle Hochschule Bayern (vhb)
- DiZ – Zentrum für Hochschuldidaktik
University Assistance System HAnS
Today, students have to play an ever more active role in their education. They can’t be passive participants, but have to set clear goals, find quick and efficient ways of working with the available materials, and more and more often utilize the freedom they have in achieving their learning objectives. This already difficult task is exacerbated by the tremendous amounts of materials that students have access to today, which they are usually required to process.
Unfortunately, traditional learning materials often fall short of the demands, which the pace of modern education places on them. Lecture recordings, for example, are useful, but not when what student needs is the 30-second segment they have to search an hour-long video for. Modular course systems are helpful, but can lead to a situation where student is simply lost and doesn’t know what to tackle next. These and many other problems lead to students who are ready and eager to learn simply being overwhelmed.
HAnS is designed to remedy that.
What does HAnS actually do?
University Assistant System (Hochschul-Assistenz-System, or simply HAnS) is a multifunctional learning platform that is meant to support students by enabling a much more efficient interaction with learning materials. It is still being actively developed, but it already offers several key benefits.
Enhanced lecture videos
HAnS platform allows teachers to upload their videos, just like any other, but using fine-tuned machine learning, HAnS makes these recordings much more useful:
- Automatic subtitle generation. No more being hindered by a bad microphone or a quite speaker.
- Lecture summarization. An automatic text summary of the lecture content allows judging at a glance what you should expect from the video and whether it contains the information you need
- Automatic table of content. A timestamped list of topics the lecture covers allows quick and efficient navigation, as well as an overview of the lecture logic.
- Intelligent search. You remember that somewhere in the 3-hour lecture the professor mentioned something about a particular topic? No problem – you will be pointed to the exact timestamps where this topic was covered, with brief transcript extract, so you can understand the context.
- Automated question generation. Student can ask for questions of different difficulty level, concerning either the lecture content in general or the topic associated with the current timestamp, and have them automatically generated, allowing to quickly test whether or not they have understood the key concepts.
- Specialized chatbot. Specifically designed for the task and supported by a robust knowledge base, this chatbot gives student a personal tutor, ready to answer any questions they might have throughout the lecture.
And the most important thing is – through machine learning, the whole process is automated and can be performed for any uploaded lecture.
Content recommendation system
While still under development, this system already keeps track of what learning activities the student took part in, to recommend related lectures and other learning materials. This ensures that the student never gets stuck on their self-guided learning journey and can always ask for advice on what to tackle next.
How to use HAnS?
Interested in trying the system out? Whether you are a student or a teacher, here we offer detailed instructions on how you should use the platform and how you can incorporate it into your teaching or learning workflow.
How does HAnS work?
While we can’t reveal all technical details, we’re happy to provide a general overview of what the system actually does:
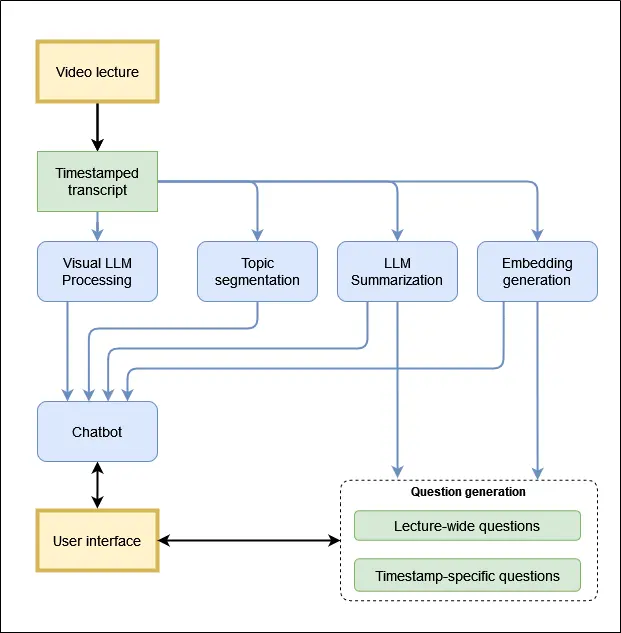
- When the lecture is uploaded, a timestamped transcript is generated for it, using voice recognition. This transcript then serves as an input for several systems.
- Visual LLM processing combines the timestamped transcript with the lecture slides, creating a context, which defines the information the chatbot provides.
- Topic segmentation separates the transcript into several key segments, based on the topic, in order to enable efficient context selection for the chatbot answer generation. The table of contents is created similarly, but utilizes a separate system, as topic segmentation for the student and for the chatbot require different degree of detail.
- LLM summarization system uses the transcript to present a brief lecture summary, enabling quick initial navigation, while also using it to enable chatbot navigation of this information.
- Finally, embedding generation and LLM summarization are used to create question. Depending on the student’s needs, the embedded context which the questions are generated from, changes. For general lecture questions there is no focus on any specific embedded segment in particular. For timestamp-specific questions, the current timestamp the student is on is utilized as one of the inputs, ensuring that the context for question generation is tied to a specific segment of the transcript and, more importantly, the topic that segment is related to.
The whole system is computationally intensive, and, considering that multiple students and teachers can be using it at once, efficient resource allocation is extremely important, both to ensure all the system segments are accessible, and to make the system as energy and resource efficient as possible. This is achieved using Scalable Engine for Reasoning, Analysis, and Prediction with Hosting (SERAPH), which dynamically allocates all the tasks described above to a set of available hardware. If you want to learn more about how it does this – take a look at the relevant papers section below!
About the project
HAnS is a joint project with 40 total contributors from 8 universities and 3 institutes across Germany. THI’s work focuses first of all on the "User perspective and acceptance" work package, ensuring that the interaction between the users and the underlying systems goes as smooth and as efficiently as possible. On top of that we are also involved in the technical development and are responsible for integrating HAnS into THI Moodle.
Project Partners

Publications
The Hochschul-Assistenz-System HAnS: An ML-Based Learning Experience Platform (2023)
Authors: Thomas Ranzenberger, Tobias Bocklet, Steffen Freisinger, Lia Frischholz, Munir Georges, Kevin Glocker, Aaricia Herygers, René Peinl, Korbinian Riedhammer, Fabian Schneider, Christopher Simic, Khabbab Zakaria
Link: https://www.essv.de/paper.php?id=1188
Abstract:
The usage of e-learning platforms, online lectures and online meetings for academic teaching increased during the Covid-19 pandemic. Lecturers created video lectures, screencasts, or audio podcasts for online learning. The Hochschul-Assistenz-System (HAnS) is a learning experience platform that uses machine learning (ML) methods to support students and lecturers in the online learning and teaching processes. HAnS is being developed in multiple iterations as an agile open-source collaborative project supported by multiple universities and partners. This paper presents the current state of the development of HAnS on German video lectures.
Unsupervised Multilingual Topic Segmentation of Video Lectures: What can Hierarchical Labels tell us about the Performance? (2023)
Authors: Steffen Freisinger, Fabian Schneider, Aaricia Herygers, Munir Georges, Tobias Bocklet, Korbinian Riedhammer
Link: https://www.isca-speech.org/archive/slate_2023/freisinger23_slate.html
Abstract:
The current shift from in-person to online education, e.g., through video lectures, requires novel techniques for quickly searching for and navigating through media content. At this point, an automatic segmentation of the videos into thematically coherent units can be beneficial. Like in a book, the topics in an educational video are often structured hierarchically. There are larger topics, which in turn are divided into different subtopics. We thus propose a metric that considers the hierarchical levels in the reference segmentation when evaluating segmentation algorithms. In addition, we propose a multilingual, unsupervised topic segmentation approach and evaluate it on three datasets with English, Portuguese and German lecture videos. We achieve WindowDiff scores of up to 0.373 and show the usefulness of our hierarchical metric.
Scalable engine and the performance of different LLM models in a SLURM based HPC architecture
Authors: Anderson de Lima Luiz and Shubham Vijay Kurlekar and Munir Georges
Link: https://www.essv.de/pdf/2025_297_304.pdf
Abstract:
This work elaborates on a High performance computing (HPC) architecture based on Simple Linux Utility for Resource Management (SLURM) [1] for deploying heterogeneous Large Language Models (LLMs) into a scalable inference engine. Dynamic resource scheduling and seamless integration of containerized microservices have been leveraged herein to manage CPU, GPU, and memory allocations efficiently in multi-node clusters. Extensive experiments, using Llama 3.2 (1B and 3B parameters) [2] and Llama 3.1 (8B and 70B) [3], probe throughput, latency, and concurrency and show that small models can handle up to 128 concurrent requests at sub-50 ms latency, while for larger models, saturation happens with as few as two concurrent users, with a latency of more than 2 seconds. This architecture includes Representational State Transfer Application Programming Interfaces (REST APIs) [4] endpoints for single and bulk inferences, as well as advanced workflows such as multi-step "tribunal" refinement.


![[Translate to English:] Logo Akkreditierungsrat: Systemakkreditiert](/fileadmin/_processed_/2/8/csm_AR-Siegel_Systemakkreditierung_bc4ea3377d.webp)



![[Translate to English:] Logo IHK Ausbildungsbetrieb 2023](/fileadmin/_processed_/6/0/csm_IHK_Ausbildungsbetrieb_digital_2023_6850f47537.webp)